
Conway’s Law, the 1967 observation that software structures mirror the communication patterns of the organizations that build them, gets cited in every architecture talk and ignored in every architecture decision. When a US agency outsources development to a Philippine team, the codebase inherits the communication constraints between those two groups whether anyone planned for it or not. The mechanism behind scalable distributed web app architecture depends on this reality: you don’t pick an architecture and then organize your team around it. You look at how your team actually communicates across time zones, and you design the system to match.
The common misunderstanding is that scaling a web app is primarily a technology problem. Pick microservices. Add Kubernetes. Deploy to the edge. The technology matters, sure. But the system will scale or collapse based on whether its internal boundaries align with the human boundaries of a distributed team. Here’s how that alignment actually works, layer by layer.
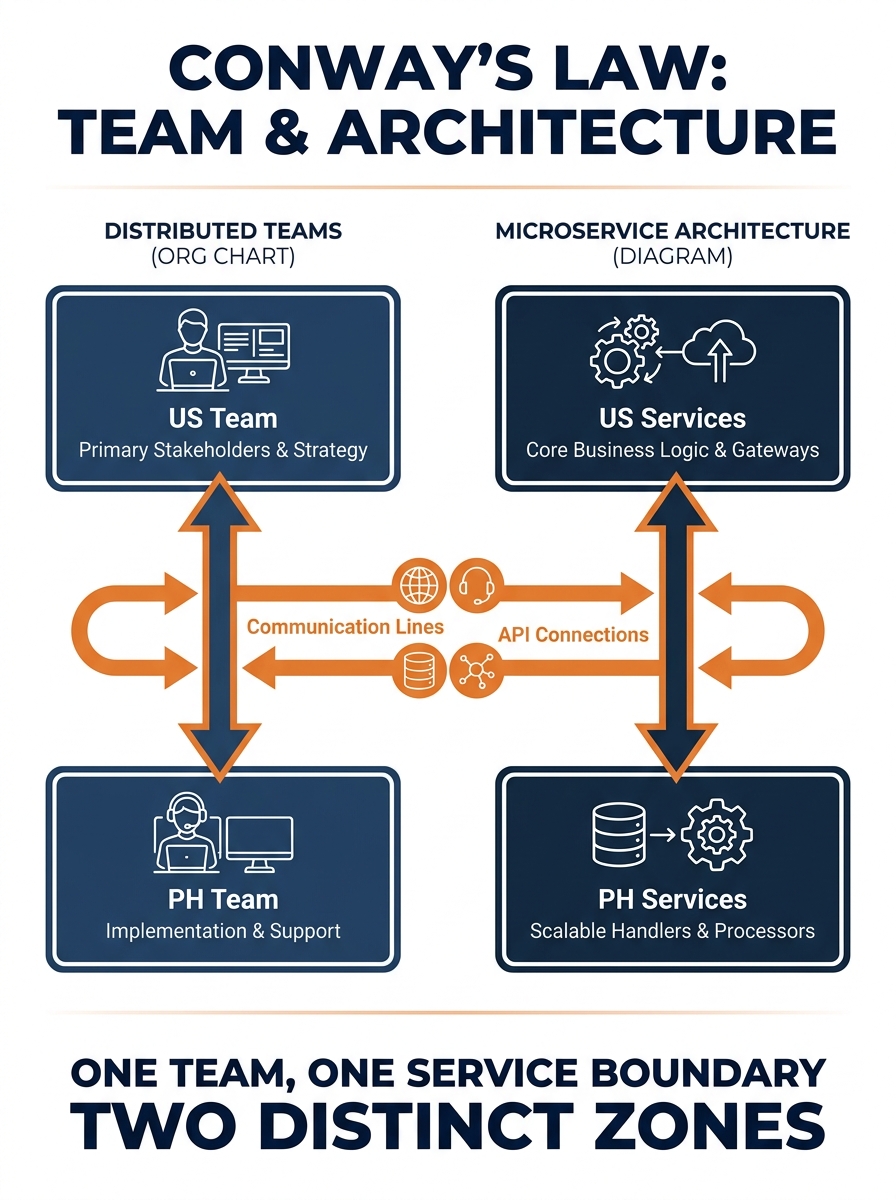
Service Boundaries Follow Team Boundaries
Chris Richardson’s service-per-team pattern formalizes what experienced distributed teams already know: a team should own exactly one service unless there’s a proven need for more. The reason is practical. When your frontend developers are in Los Angeles and your backend developers are in Cebu, every shared dependency between their codebases creates a coordination cost. That cost is measured in Slack messages sent during someone else’s sleep, pull requests that sit unreviewed for 14 hours, and deployment schedules that require both teams online simultaneously.
Microsoft’s Azure architecture documentation makes the same point from a different angle: a microservices architecture avoids sharing code or data stores between services, which minimizes dependencies and lets teams pick the technologies that fit their specific problem. If your Philippine development team is strong in Node.js and your US-side architect prefers Go for certain backend services, a properly bounded microservices setup accommodates both without compromise.
The practical output of this principle is straightforward. Map each service to a team. Give that team full ownership: code, database, deployment pipeline, and on-call rotation. When you’re working with offshore web developers, this mapping becomes the architectural decision that matters more than any framework choice.
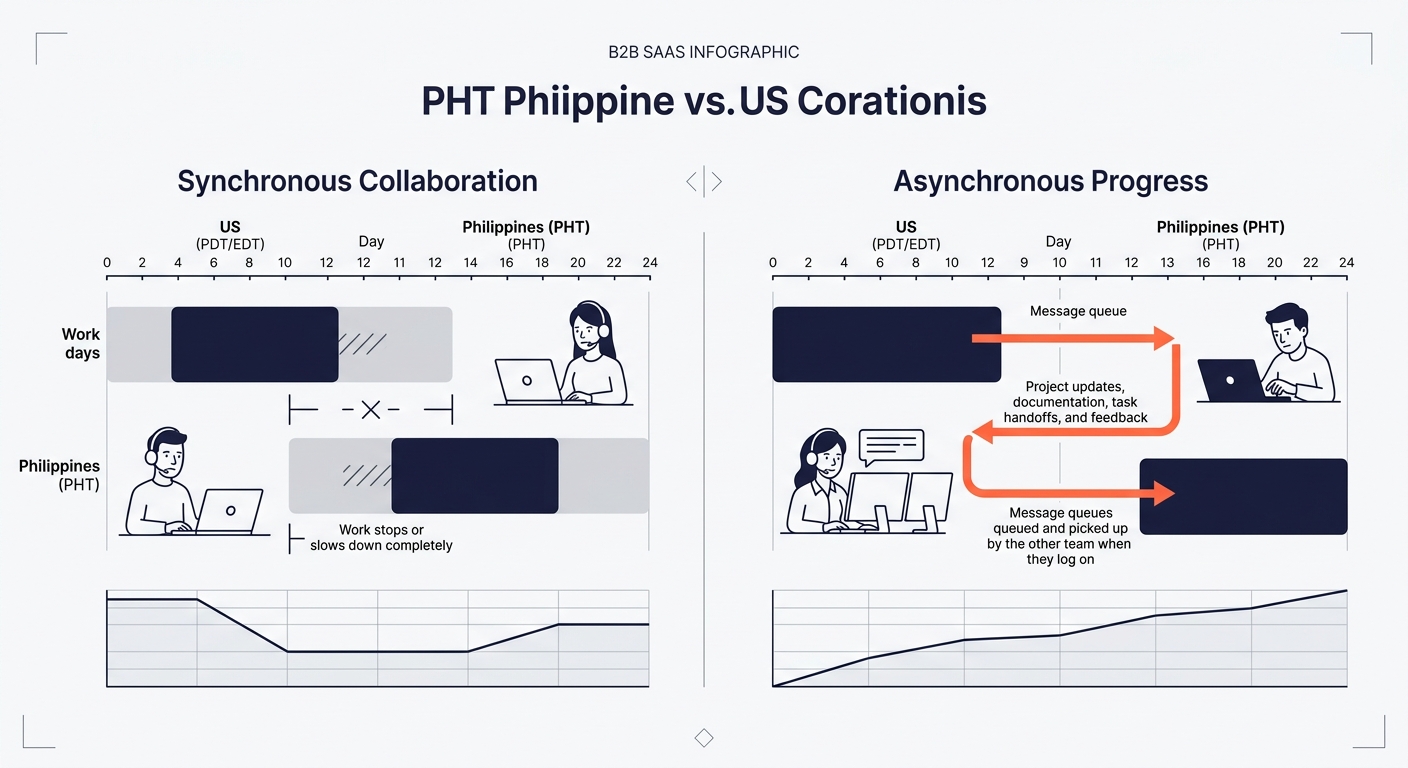
How Async Messaging Prevents Time-Zone Deadlocks
The 8-13 hour gap between US Pacific Time and Philippine Standard Time is either your biggest constraint or your biggest advantage. It depends entirely on whether your codebase is designed for asynchronous communication.
In a synchronous architecture, Service A calls Service B and waits for a response. If the team responsible for Service B is asleep when Service A breaks, everything stops. In an async-friendly codebase design, Service A drops a message on a queue (RabbitMQ, Kafka, AWS SQS) and moves on. Service B processes that message whenever it’s ready. The system stays responsive regardless of which humans are awake.
Asynchronous programming patterns provide the foundation for building responsive, scalable applications, and the benefits compound when the team itself operates asynchronously across time zones. The Saga pattern, for instance, implements distributed operations as a series of local transactions rather than a single coordinated call. Each service completes its piece independently and publishes an event. No service blocks waiting on another.
The economics are concrete. A team that can ship work continuously across a 16-hour combined workday (8 hours US, 8 hours Philippines, with 3-4 hours of overlap) moves roughly 40% faster on feature delivery than a co-located team of the same size. But only if the codebase supports it. If your architecture requires synchronous handoffs, your distributed team will spend those overlap hours in meetings trying to coordinate instead of coding.
When communication costs in outsourced web development become a bottleneck, the fix is usually architectural, not managerial. You don’t solve time-zone friction with more standups. You solve it with message queues.
API Contracts as the Coordination Layer
When two developers sit in the same office, they resolve interface questions in a five-minute hallway conversation. When one developer is in Austin and the other is in Manila, that same question becomes a 14-hour round trip. API contracts eliminate the round trip.
An API-first approach means defining the contract (inputs, outputs, error codes, versioning) before writing any implementation code. Tools like OpenAPI specifications make the contract machine-readable, so both teams can generate client libraries, mock servers, and test suites from a single source of truth. The Manila team builds against the mock while the Austin team implements the real service. No blocking.
This is where microservices outsourcing either works well or falls apart. Without a contract, every ambiguous endpoint becomes a scope creep vector that compounds across time zones. With a contract, the Philippine team has everything they need to build, test, and ship their service independently.
The architecture decisions that determine whether a distributed team ships fast or ships late are almost never about which framework you chose. They’re about how explicitly you defined the boundaries between what each team owns.
What a Good Contract Covers
A production API contract specifies response schemas for success and error cases, pagination behavior, authentication requirements, rate limits, and deprecation policies. Teams that skip any of these end up burning their overlap hours on clarification calls instead of code review.
Version your APIs from day one. When Service A depends on Service B’s v1 endpoint, Service B’s team can ship v2 without breaking anything. The Philippine team upgrades at their own pace, during their own working hours.
CI/CD Pipelines Replace Synchronous Coordination
Automated pipelines replace the coordination you used to do in meetings. When a developer in Cebu pushes code at 6 PM Philippine time, the pipeline runs tests, checks code quality, builds a container image, and deploys to staging without anyone in the US needing to be awake.
For scalable app infrastructure, the pipeline typically includes:
- Automated linting and formatting checks (catches style disagreements before code review)
- Unit and integration tests against the service’s own database
- Contract tests that verify the service still satisfies its API specification
- Container build and push to a registry
- Automated deployment to a staging environment
- Smoke tests against staging
Contract tests (step 3) are the critical piece for distributed teams. They verify that when Service A’s team changes their output format, Service B’s expectations still hold. Without contract tests, you discover integration failures during manual QA, which in a distributed setup means a 24-hour feedback loop before anyone can act on the result.
Filipino developers trained in modern DevOps workflows handle this tooling well. Many Philippine development teams building production architecture already work with containerized deployments and GitOps patterns as their default setup.
Caching and Edge Deployment for Global Users
When your development team spans two continents, your users probably do too. Scalable app infrastructure puts content delivery and computation close to end users, not close to your primary data center.
CDNs (Cloudflare, CloudFront, Fastly) cache static assets at edge locations and reduce origin server load by up to 70% during traffic spikes. For dynamic content, Redis or Memcached can drop database read latency from 100ms to 2ms for frequently accessed data. Edge compute platforms like Cloudflare Workers or Vercel Edge Functions run application logic in 300+ locations worldwide.
The distributed-team benefit here is operational. Edge infrastructure is managed infrastructure. Your team doesn’t maintain servers in multiple regions. They deploy code, and the platform handles distribution. This reduces the ops burden on a team that’s already coordinating across time zones, freeing developers to focus on feature work rather than infrastructure firefighting.
Tip: If your app serves users in both the US and Southeast Asia, edge caching alone can cut global page load times by 30-50%. Configure your CDN to cache API responses for read-heavy endpoints, and you’ll reduce the load on your origin servers enough to defer your next infrastructure scaling decision by months.
Where the Model Breaks
This architecture has failure modes that show up reliably around month six of a growing application.
Data consistency across services. Async messaging means eventual consistency, not immediate consistency. If your product requires that a user’s account balance update instantly across every service, you’ll fight the architecture instead of working with it. Financial transactions, inventory counts, and anything requiring strict ordering need careful Saga design or synchronous fallbacks for specific operations.
Debugging distributed failures. When a request touches five services and something goes wrong, tracing the failure across service boundaries requires investment in observability tooling (distributed tracing, centralized logging, correlated request IDs). Without this investment, your team spends overlap hours on incident calls instead of shipping features.
Premature decomposition. Splitting into microservices before you understand your domain boundaries produces services that need constant cross-team coordination, which defeats the entire purpose. If your product is pre-product-market-fit and requirements change weekly, a well-structured monolith with clear internal module boundaries will serve you better. You can extract services later, once the boundaries stabilize.
Team size mismatch. The service-per-team model assumes teams of 4-8 people. If you’re running a 2-person Philippine team alongside a solo US architect, you don’t have enough people to own independent services. A modular monolith with clear ownership boundaries over internal modules is the honest architecture for a team that size.
The mechanism works when you respect its constraints: stable domain boundaries, adequate team size per service, investment in observability, and a genuine need for independent deployment. Skip any of those prerequisites, and you’ll spend more time managing the architecture than building the product. Understanding where this model fails before you adopt it is what separates teams that scale gracefully from teams that learn the same lesson at $80,000 in rework costs.