
Technical debt can represent 20–40% of a company’s total technology estate value, according to a Leanware analysis of development economics, and engineers spend roughly a third of their time servicing it instead of writing new features. For agencies that rely on Philippine web development teams to build their social media marketing infrastructure (campaign landing pages, tracking integrations, social commerce storefronts), the mechanism that prevents this debt from accumulating matters more than any individual coding standard or style guide.
The common misunderstanding is that speed and code quality sit on opposite ends of a slider. Move fast, accumulate debt. Write clean code, miss deadlines. Philippine dev teams that consistently ship production-ready code on tight marketing timelines operate on a different model entirely. They enforce quality automatically at multiple checkpoints so that speed becomes a byproduct of discipline rather than a substitute for it.
Here’s how that mechanism works, layer by layer.
Automated Quality Gates Catch Debt Before It Ships
The first layer is the CI/CD pipeline, and it’s where most technical debt prevention actually happens. When a developer pushes code for a new campaign landing page or updates a tracking pixel integration, the pipeline runs a series of automated checks before that code can merge into the main branch.
These checks typically include:
- Linting and static analysis that enforce consistent code style and catch common errors
- Unit and integration tests that verify the new code doesn’t break existing functionality
- Performance audits (often using Lighthouse) that flag pages exceeding load-time thresholds
- Security scans that identify vulnerabilities before they reach production
As Atlassian’s technical debt framework emphasizes, strict definitions of done, automated testing, and continuous integration are the primary controls that keep debt from entering the codebase in the first place. Prioritizing and addressing technical debt within sprints prevents the quality decline and delivery delays that compound over months.
The key detail: none of these checks require human judgment in the moment. They run every time, on every commit. A developer working at 2 AM in Manila to get a campaign microsite ready for a US-timezone launch can’t accidentally skip the performance check because they’re tired. The pipeline either passes or it doesn’t.

For social media marketing teams, this matters because campaign assets change constantly. You’re swapping hero images, updating CTAs, and testing new landing page layouts on a weekly basis. Each of those changes is an opportunity to introduce technical debt. Automated gates ensure every change goes through the same quality filter regardless of how urgent the campaign deadline feels.
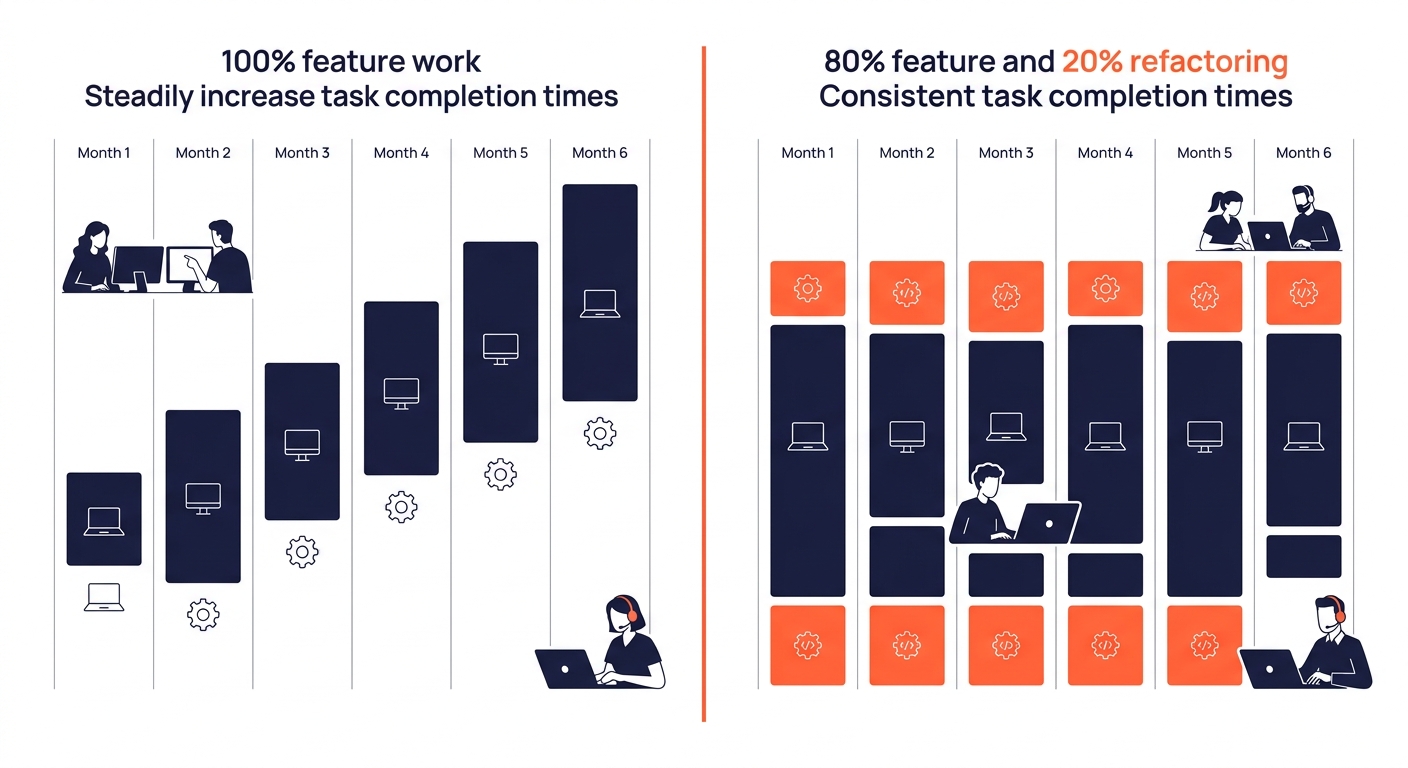
Allocating 20% of Sprint Capacity to Refactoring
Automated checks catch obvious problems. They don’t catch architectural drift, where the codebase slowly becomes harder to work with as features accumulate without structural improvements.
The standard practice among mature Philippine dev teams is to dedicate roughly 20% of each sprint’s capacity to refactoring and debt reduction. Some teams run focused “swarm” sprints where the entire group tackles accumulated debt items, but the more common approach is a steady allocation: one day out of every five goes to improving existing code rather than shipping new features.
This sounds expensive until you look at what happens without it. Code that doesn’t get refactored becomes progressively slower to modify. A landing page template that took two hours to customize in January takes six hours by June because someone hardcoded values that should have been configurable, and someone else added a third-party script without considering load order.
A landing page template that took two hours to customize in January takes six hours by June when refactoring gets skipped.
For agencies running social media campaigns across multiple clients, this compounding effect is brutal. If your outsourced WordPress development team builds five client microsites on the same base template, a shortcut taken once gets multiplied across all five properties. The 20% refactoring allocation is what keeps that base template clean enough to reuse without accumulating problems that slow down every future campaign launch.
Writing production-ready code means adopting best practices that prioritize readability, maintainability, performance, and security from the start. When those practices get embedded into the sprint rhythm rather than treated as aspirational ideals, the web development best practices actually stick.
Why Modular Architecture Accelerates Campaign Iteration
Production-ready code follows a principle that sounds academic but has very practical consequences: modularity. Each component of a web application should do one thing, do it well, and be replaceable without affecting the rest of the system.
The Bulletproof React architecture, an open-source project structure widely referenced by Philippine dev teams, demonstrates this approach well. It organizes a React application into features, components, and services that are loosely coupled. When a social media marketing team needs to add a new conversion tracking integration, the developer modifies the tracking service module without touching the page layout, the form handlers, or the content management layer.
This modularity is what makes scalable web architecture possible when your development team is distributed across time zones. As we’ve covered in our breakdown of building scalable systems with distributed teams, the architecture has to absorb change without cascading side effects. A developer in Cebu can update the analytics module while a developer in Davao builds a new landing page component, and neither blocks the other.
Following SOLID principles and keeping code well-documented means a new team member can understand any given module without reading the entire codebase first. This is especially critical in outsourced engagements where team composition may shift over the life of a long-running marketing account. Version control through Git supports collaborative development and allows easy rollbacks if a campaign change introduces problems.
Change Control Doubles as a Code Quality Boundary
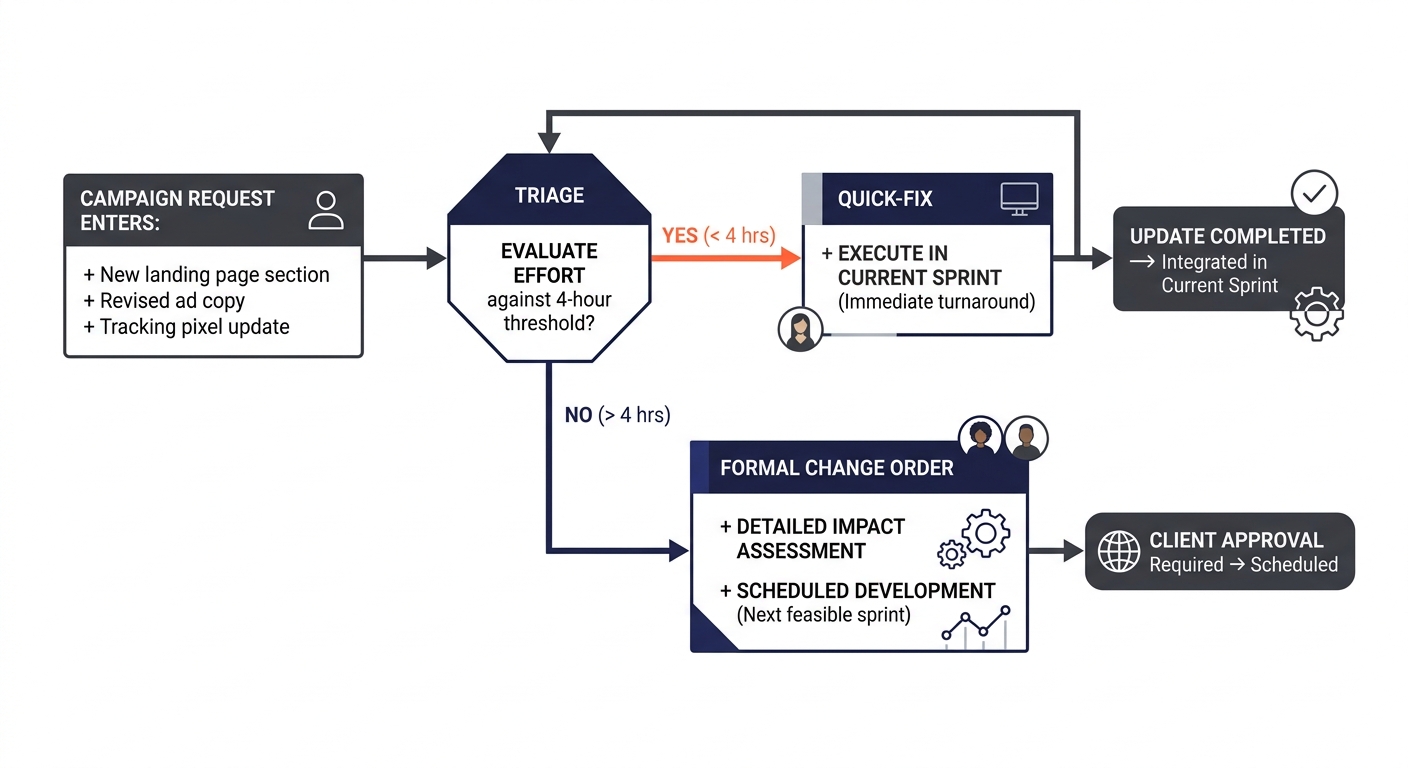
Speed pressure in social media marketing campaigns creates a specific failure mode: ad-hoc scope additions that bypass the development process. The campaign manager says “can you just add a popup for this offer?” and the developer implements it inline without creating a reusable component, without writing tests, without updating documentation. Multiply this by twenty requests over three months and the codebase becomes a patchwork of one-off hacks.
Philippine dev teams that maintain code quality under campaign pressure use an explicit change control mechanism. Every request above a defined threshold (typically four hours of development time) triggers a written change order with timeline and cost impact stated upfront. The client sees the tradeoff before approving. This approach, detailed in our analysis of how scope creep derails web development projects, prevents the most common source of technical debt in marketing web properties: undocumented changes made under time pressure.
The structured async protocols these teams use reinforce the boundary further. Every open question gets logged in a shared tracker with an owner and a 48-hour deadline. When a US-based marketing director asks for a change at 4 PM Eastern, it doesn’t get handled as an urgent interruption at midnight Manila time. It enters the same tracked workflow as every other request, which means it receives the same quality treatment.
Tip: If you’re running social media campaigns that require frequent landing page updates, establish the four-hour threshold with your dev team during onboarding. Requests under four hours flow through normal sprint work. Requests over four hours get a written change order. This single rule prevents most campaign-driven technical debt.
This pairs directly with how effective teams run stakeholder workshops to keep alignment between marketing goals and development execution throughout the engagement.
Where the Model Breaks Down
This mechanism works well in steady-state operation, where sprint rhythms are established, the CI/CD pipeline is configured, and both the marketing team and the dev team understand the change control process. It breaks down in specific, predictable ways.
The first sprint is the most vulnerable. Setting up the CI/CD pipeline, configuring quality gates, establishing the component library, and writing the first set of tests takes real time. Teams that try to ship production features during sprint one while simultaneously building the quality infrastructure end up with shortcuts baked into the foundation. The fix is straightforward but requires client buy-in: the first sprint produces infrastructure rather than visible features. You can understand how defining project scope upfront directly determines whether this setup sprint gets protected or sacrificed.
Campaign emergencies override process. When a social media campaign goes viral unexpectedly and the landing page needs to handle 10x normal traffic by tomorrow morning, the change control process gets abandoned. Good teams accept this reality but tag every emergency change for retroactive review in the next sprint’s refactoring allocation. The debt still enters the codebase. The difference is whether it gets cleaned up in two weeks or festers for six months.
The 20% allocation erodes under deadline pressure. Product owners and marketing directors who don’t understand how technical debt compounds will regularly ask to redirect refactoring time toward feature work. This works for one or two sprints. By the third sprint of deferred maintenance, velocity drops measurably, and the team spends more time working around problems than they saved by skipping refactoring.
Warning: If your team has skipped refactoring allocation for three consecutive sprints, expect a 15–25% velocity drop in sprint four. The compounding is real, and it hits your campaign turnaround times directly.
Cross-timezone communication gaps create specification debt. When the Manila team interprets a campaign requirement differently than the LA marketing director intended, the resulting code works but builds toward the wrong goal. Structured scope definition processes reduce this risk but can’t eliminate it entirely. Regular screen-share reviews where the dev team demonstrates work in progress catch misalignment before it calcifies into the architecture.
The model also doesn’t scale infinitely. A five-person Philippine dev team supporting two or three agency clients can maintain this discipline with their existing leadership structure. A fifteen-person team supporting eight clients needs dedicated DevOps and QA roles to keep the quality gates maintained and the refactoring allocation protected from erosion.
The mechanism behind production-ready code from Philippine dev teams isn’t mysterious. It’s automated quality enforcement at the pipeline level, protected refactoring time at the sprint level, modular architecture at the design level, and explicit change control at the process level. Each layer compensates for the weaknesses of the others. Automated tests catch individual code problems but miss architectural drift, so refactoring time addresses that. Refactoring keeps the codebase healthy but doesn’t prevent scope chaos, so change control addresses that instead. When one layer fails temporarily (and it will, especially during campaign surges), the remaining layers prevent a single bad sprint from creating months of accumulated debt that slows every future campaign you try to run.