
Centralized cloud deployments add 50 to 150 milliseconds of network latency depending on geographic distance and congestion, according to research on AI model latency and telco infrastructure. That number sounds trivial until you stack it on top of unoptimized database queries, bloated asset bundles, and a PHP backend that nobody has profiled in six months. When your development team sits 7,000 miles from your primary user base, every layer of the stack compounds. Application responsiveness degrades in ways that are hard to diagnose because the slowdown lives partly in the code, partly in the infrastructure, and partly in the collaboration patterns between your onshore and offshore teams.
These seven rules are how you find and fix those distributed development bottlenecks before your users notice them and your revenue shows it. They apply whether you’re running a three-person offshore PHP team or a fifteen-person cross-functional squad split between Sydney and Manila.
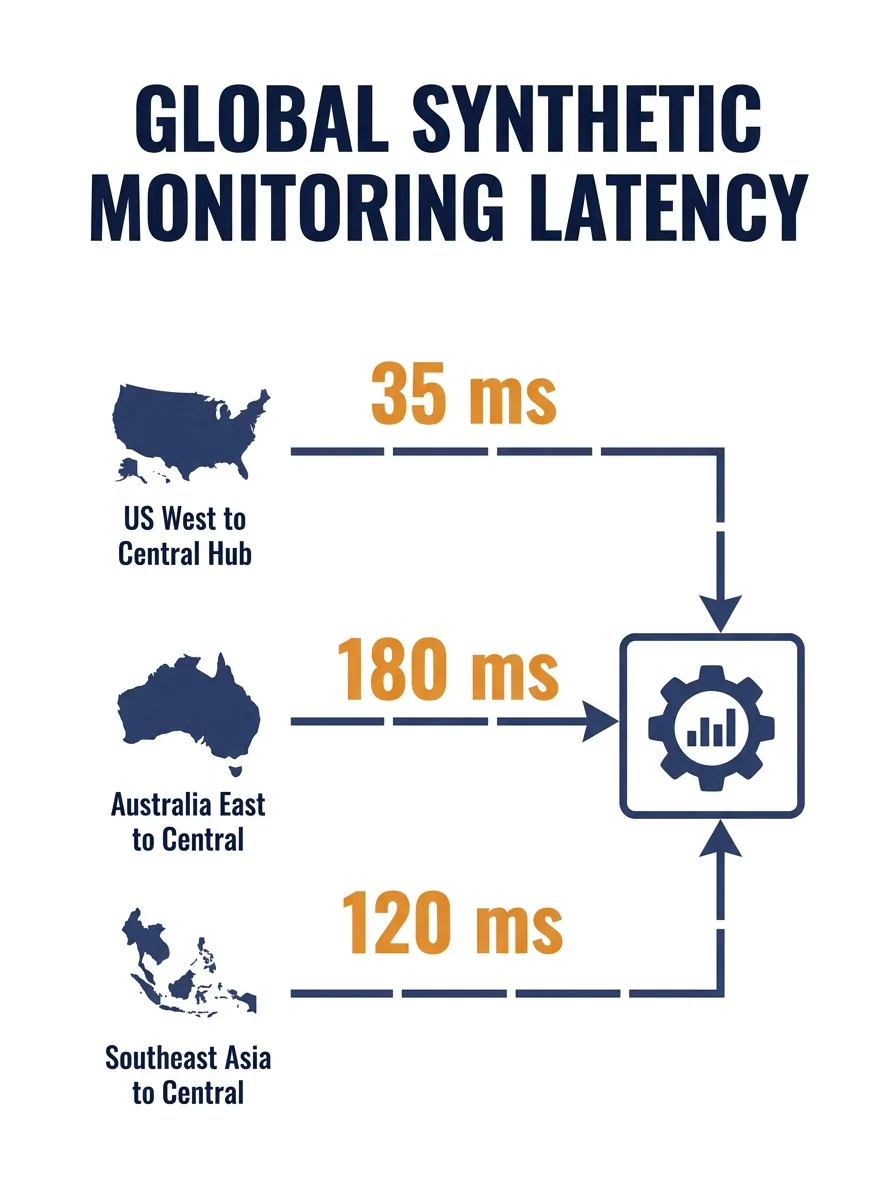
Always measure from where your users sit, not where your servers live
Your developers in the Philippines will tell you the app loads fine. They’re right. It does load fine from Southeast Asia, especially if your staging server is in Singapore. The problem is your customers are in Phoenix, or Melbourne, or Chicago.
Set up synthetic monitoring from your users’ actual regions. Tools like WebPageTest and Catchpoint let you run performance checks from specific geographic nodes. Real User Monitoring (RUM) goes further by capturing actual page load data from real sessions. When you’re reviewing web app performance metrics, the numbers that matter are the ones recorded at the end-user’s browser, not at the origin server.
A common mistake is running Lighthouse audits locally and calling it good. Lighthouse tells you about code-level optimization opportunities. It tells you nothing about how your CDN behaves under load from Dallas at 2 PM on a Tuesday.
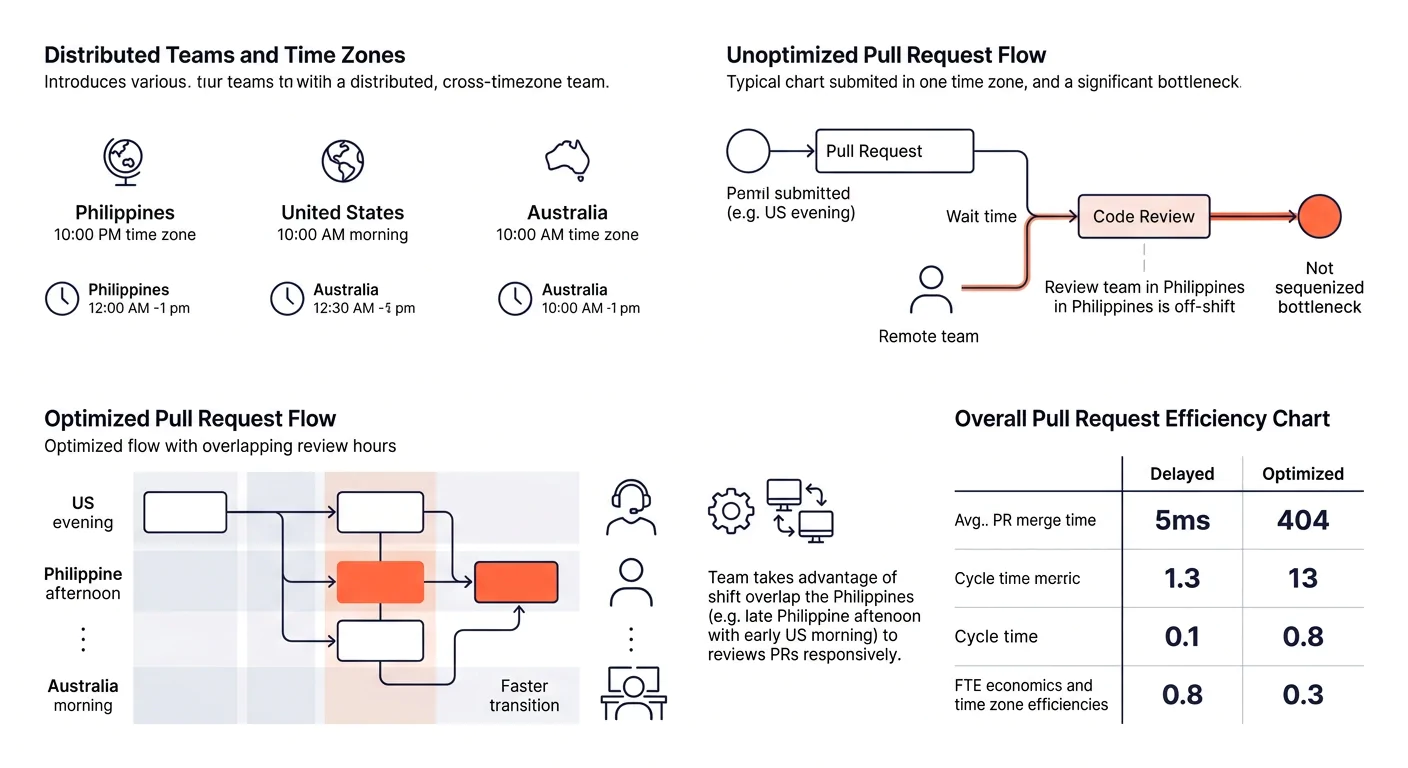
Treat time-zone overlap as a performance variable, not a scheduling convenience
When a developer in Manila encounters a performance regression at 3 PM their time, it’s midnight in New York. If the fix requires access to production infrastructure that only the US-side lead can grant, that regression ships to real users for eight or more hours. That’s a distributed development bottleneck that no amount of code optimization can solve.
The fix is structural. Establish a “Golden Hour” window of at least three hours of daily overlap where both sides of the team are awake and available. Use that window for code reviews, deployment decisions, and anything that touches production monitoring. Outside that window, your offshore team needs autonomy to act on performance issues without waiting for approval.
This is where clear communication protocols prevent expensive delays. A runbook that says “if P95 latency exceeds 400ms, roll back the last deploy and open a ticket” gives your Manila team the authority to act at 3 PM their time without waking anyone up.
Profile at the function level before blaming the network
Nine times out of ten, when someone says “the app is slow because our team is offshore,” the actual problem is a badly written database query or an N+1 loop buried three layers deep in the codebase. Geographic distance is real, but it’s rarely the primary cause of user-facing slowness.
PHP developer performance tools like Blackfire give you function-call-level profiling that shows exactly where each request spends its time. Blackfire’s deterministic profiling captures metrics at the individual function level, so you can see whether your 800ms response time comes from a slow API call, an unindexed query, or a template rendering loop that iterates 4,000 times.
MiniProfiler is a lighter-weight alternative that shows where your PHP application spends time during each request. For teams tracking average latency, error rate, and requests per second, these tools make the invisible visible.
The discipline here is to always instrument before you speculate. When your staging environment in Singapore responds in 120ms and production in Virginia responds in 600ms, profiling will tell you whether those extra 480ms come from network hops or from code paths that behave differently under production data volumes.
Tip: Run profiling against production-sized datasets, not the 50-row test database your developers use locally. Performance problems that only appear at scale are the ones that actually hurt your business.
Make Core Web Vitals a contract KPI, not a quarterly audit
Core Web Vitals (Largest Contentful Paint, Interaction to Next Paint, Cumulative Layout Shift) are now standard KPIs in well-run offshore engagements. If your contract with your Philippine development team doesn’t include performance targets, you’re managing by hope.
Here’s what a practical performance SLA looks like: LCP under 2.5 seconds at the 75th percentile from US-based RUM data. INP under 200 milliseconds. CLS under 0.1. These numbers come straight from Google’s thresholds, and they’re measurable, auditable, and tied to actual search ranking impact.
When you build scalable systems with a distributed development team, baking these metrics into the definition of “done” means performance never becomes an afterthought. A feature that ships with an LCP regression from 2.2 seconds to 3.8 seconds isn’t done. It’s broken.
A feature that ships with an LCP regression from 2.2 seconds to 3.8 seconds isn’t done. It’s broken.
Wire your CI/CD pipeline to run Lighthouse CI on every pull request, with hard failure thresholds for each Core Web Vital. Your offshore team gets immediate feedback, and regressions get caught before they reach staging.
Fix the review queue before you fix the code
Research from Gun.io on remote developer productivity found that successful distributed organizations look at systemic patterns rather than individual output. The question isn’t “is this developer slow?” The question is “are code reviews becoming a bottleneck? Are certain teams consistently blocked by dependencies?”
In distributed teams, the review queue is where productivity goes to die. A pull request opened at 5 PM Manila time sits untouched until 9 AM New York time. The developer context-switches to something else. By the time review comments come back, they’ve lost the mental model of what they wrote. Fixes take twice as long.
The data backs this up. Studies of 200+ distributed teams found that uneven distribution of high-complexity work leads to 67% higher burnout and 45% more production incidents within six months. When three developers handle 80% of the complex reviews, they become a single point of failure for your entire velocity.
Solve this by distributing review responsibility explicitly. Assign reviewers by rotation, set a 4-hour SLA on initial review response during working hours, and use automated linting and type checking to handle the mechanical stuff so human reviewers can focus on logic and architecture. Teams that ship production-ready code from day one tend to have review processes that catch problems early without creating week-long queues.
Put your CDN and caching strategy in writing on day one
This rule sounds obvious. In practice, caching strategy is the thing that gets figured out “later” and then causes 40% of your performance complaints in production.
For distributed teams, your CDN configuration matters more than it would for a co-located team, because misconfiguration is harder to diagnose across time zones. Document these decisions explicitly: which assets get edge-cached and for how long, what cache-busting strategy you use for deploys, whether your API responses use ETags or Cache-Control headers, and how you handle cache invalidation for dynamic content.
Prefer Nginx or LiteSpeed over Apache for serving static assets. The performance difference under concurrent load is measurable and meaningful, especially for PHP applications where the web server and the application runtime interact closely.
Database-level caching matters equally. Connection pooling, query result caching, and proper indexing should be part of your offshore team’s onboarding checklist. A well-indexed PostgreSQL query that returns in 12ms can become a 1,200ms disaster when a new developer adds a filter on an unindexed column and nobody catches it in review. This connects back to the previous rule: your review process needs to include performance awareness, and your team needs access to observability platforms that surface slow queries before they ship.
Automate the performance feedback loop into every deploy
Manual performance testing doesn’t scale across time zones. By the time someone in New York runs a load test on code deployed by the Manila team, the context is gone and the finger-pointing starts.
Build performance checks into your deployment pipeline. Every merge to main triggers a synthetic performance test from at least two geographic regions. Results post automatically to your team’s Slack or Teams channel. If P95 latency degrades by more than 15% compared to the previous deploy, the pipeline flags it.
Tools for this aren’t exotic. Lighthouse CI handles front-end metrics. For back-end application responsiveness, most APM tools (Datadog, New Relic, Dynatrace) support deployment markers that correlate performance changes with specific releases. Dotcom-Monitor provides end-to-end monitoring specifically designed for distributed systems, with customizable alerting and performance dashboards.
The goal is removing humans from the “did this deploy make things slower?” question entirely. Your offshore team optimization depends on fast, automated feedback that doesn’t wait for someone in a different time zone to run a manual check.
This pattern fits well with how experienced Philippine development teams already work. The ones who avoid accumulating technical debt while maintaining velocity tend to rely heavily on automated quality gates rather than manual sign-offs.
When These Rules Contradict Each Other
They will. Profiling at the function level takes engineering time that could go toward shipping features. Making Core Web Vitals a hard gate on every PR slows down your deploy frequency. Requiring three-hour daily overlap windows limits your ability to hire the best developer regardless of their location within the Philippines.
The resolution is to prioritize by business impact. If your app’s revenue correlates directly with page load time (e-commerce, SaaS with a free trial), Core Web Vitals gates and aggressive CDN caching take priority. If your bottleneck is shipping speed for a product that hasn’t found market fit yet, loosen the performance gates and tighten the review queue rules instead.
What you can’t do is ignore all seven rules and hope the performance problems sort themselves out when the team “matures.” Distributed development bottlenecks compound over time. A 200ms regression per quarter means your app is a full second slower by year’s end, and by then the problem is architectural rather than fixable with a quick optimization pass. Measure early, measure automatically, and give your offshore team the tools and authority to act on what the measurements reveal.